API шлюзу Kubernetes для оптимізації маршрутизації LLM

Сучасні сервіси генеративного штучного інтелекту та великі мовні моделі (LLM) ставлять нові вимоги до маршрутизації трафіку, які традиційні HTTP балансувальники навантаження не можуть задовольнити. Сесії інференсу LLM є тривалими, ресурсоємними та частково станом: сервери моделей на базі GPU зберігають кеші токенів в пам’яті, контексти сесій та адаптерні пайплайни. Щоб відповісти на ці вимоги, Gateway API Inference Extension розширює Kubernetes Gateway API, надаючи специфічні примітиви маршрутизації для інференсу, перетворюючи будь-який сумісний контролер входу на спеціалізований Inference Gateway.
Мотивація та Виклики
На відміну від безстатевих HTTP навантажень, інференс AI/ML вимагає:
- Балансування навантаження, обізнаного про моделі, яке враховує використання пам’яті GPU, довжину черги по кожній моделі та сумісність адаптерів.
- Афінітет сесії для чат-додатків, що дозволяє повторно використовувати кеші токенів і зменшувати витрати на холодний старт.
- Пріоритизацію на основі критичності (наприклад, інтерактивний чат проти пакетного оцінювання).
- Безпечні канаркові або блакитно-зелені розгортання нових версій моделей без втрати запитів.
Оператори часто створюють індивідуальні рішення — кастомні фільтри Envoy, розширення планувальника Kubernetes або зовнішні маршрутизатори трафіку — але бракує стандартизованого, екосистемного підходу. Inference Extension пропонує рідні CRD та точки розширення, які безшовно інтегруються з контролерами Gateway API, такими як Envoy, Contour та Kong.
Gateway API Inference Extension
Inference Extension додає два нові CRD — InferencePool та InferenceModel — які відповідають конкретним ролям користувачів та платформи:
InferencePool: Визначає масштабований пул подів (наприклад, сервери GPU або TPU) з загальними обмеженнями ресурсів, мітками GPU (NVIDIA T4, A100, H100) та політиками прийому. Адміністратори платформи можуть додавати PodDisruptionBudgets, ResourceQuotas та NodeSelectors у Kubernetes для забезпечення відповідності та ізоляції навантажень.
InferenceModel: Дозволяє командам AI/ML публікувати точку доступу model-as-a-service — з ідентифікацією моделі (наприклад, “gpt-4-chat:v2”), необов’язковими конфігураціями LoRA/адаптера та правилами розподілу трафіку (канаркові, AB-тести). Цей CRD прив’язується до одного або кількох InferencePools і відкриває детальні класи пріоритетів.
Розділяючи де моделі працюють (InferencePool) від що надається (InferenceModel), команди отримують ясність та ізоляцію між інфраструктурою та доменами даних.
Як це працює
Inference Gateway розширює стандартний робочий процес Gateway API, вставляючи точки розширення, обізнані про інференс, під час маршрутизації:
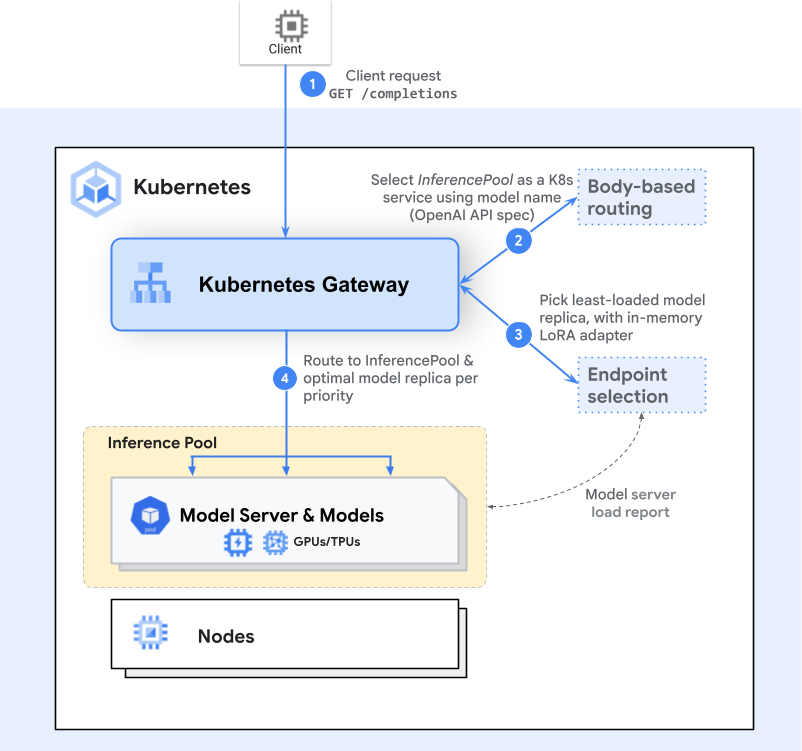
- Маршрутизація Gateway: Клієнт надсилає запит HTTP(S) (наприклад, POST /v1/completions). Контролер Gateway (Envoy, Istio Gateway) знаходить HTTPRoute, яка посилається на InferencePool.
- Розширення вибору кінцевої точки (ESE): Це розширення запитує живі метрики — використання GPU через NVIDIA DCGM, довжину черги по подах через Prometheus, завантажені метадані адаптерів через gRPC перевірки стану — щоб оцінити кандидатів на кінцеві точки.
- Інференс-обізнаний планувальник: Виходячи з динамічних метрик та прапорців критичності для кожного запиту, розширення обирає оптимальний под. Запити високого пріоритету можуть перервати запити низького пріоритету в межах одного пулу.
- Пересилання: Трафік маршрутизується через IP:порт вибраного пода з заголовками афінітету сесії (наприклад,
stickiness.cookie), зберігаючи стан в пам’яті на час сесії чату.
Бенчмарки та Аналіз Продуктивності
Ми протестували ESE в порівнянні з базовим сервісом Kubernetes для розгортання vLLM на чотирьох GPU NVIDIA H100 (80 ГБ). Використовуючи Latency Profile Generator та набір даних ShareGPT, ми поступово збільшували трафік з 100 до 1,000 QPS. Ключові результати:
- Паритет пропускної здатності: ESE підтримував пропускну здатність в межах 1–2% від базового рівня на всіх рівнях QPS.
- Зменшення затримки на кінці: При >500 QPS затримка генерації токенів p90 покращилася до 30%, зменшуючи черги запитів на насичених GPU.
- Ефективність використання ресурсів: Динамічна маршрутизація призвела до 15% вищого використання GPU, мінімізуючи простої та повторні спроби перевантаження.
“Рішення ESE щодо планування в реальному часі вирівнюють криві використання GPU, що призводить до більш плавних профілів затримки,” зазначає доктор Олена Рамос, провідний ML-інженер в Acme AI.
Питання Безпеки
Безпечний інференс вимагає:
- Взаємний TLS між Gateway та серверами моделей через токени ServiceAccount Kubernetes та сертифікати, видані cert-manager.
- Політики контролю доступу на основі ролей (RBAC) для об’єктів InferenceModel та InferencePool, щоб запобігти несанкціонованому створенню кінцевих точок.
- Правила NetworkPolicy, що ізолюють трафік інференсу до затверджених простору і обмежують вихід до зовнішніх сховищ моделей.
У майбутніх випусках планується інтеграція управління секретами для ваг моделей та конфіденційних обчислювальних enclaves (наприклад, Intel SGX, AMD SEV) для розгортання чутливих даних.
Найкращі практики експлуатації
При розгортанні Gateway API Inference Extension на великій шкалі, враховуйте:
- Горизонтальний автоскейлер подів (HPA), підключений до кастомних метрик: використання пам’яті GPU, затримка черги та час завантаження моделі.
- Автоскейлер кластера з групами вузлів, обізнаними про GPU, для забезпечення резервної потужності під час пікових навантажень.
- Інтеграцію з MLOps пайплайнами (Kubeflow, Argo CD) для автоматизованого розгортання моделей та відстеження версій.
- Розподілене трасування (OpenTelemetry) через Gateway, логіку розширення та сервери моделей для спостереження від початку до кінця.
Дорожня карта
У міру просування проекту до GA, заплановані наступні функції:
- Балансування з урахуванням кеша префіксів, що інтегрує віддалені кеші токенів.
- Пайплайни адаптерів LoRA для автоматизованих розгортань тонкої настройки.
- Політики справедливості та пріоритету для змішаних навантажень.
- Інтеграція HPA з використанням кастомних метрик для кожної моделі.
- Підтримка мультимодальних моделей (зображення, аудіо, текст).
- Гетерогенні пулі прискорювачів (наприклад, GPU, TPU, FPGA).
- Розподілене обслуговування для незалежного масштабування етапів кодувальника/декодувальника.
Резюме
Gateway API Inference Extension приносить управління трафіком, рідне для Kubernetes, до інференсу AI/ML. Завдяки маршрутизації, обізнаній про моделі, пріоритизації критичності та плануванню в реальному часі, оператори платформ можуть ефективно та безпечно самостійно розгортати GenAI/LLMs — в той час як науковці даних зберігають простоту у використанні сервісно-орієнтованих точок доступу.
Почніть: Відвідайте документацію проекту, ознайомтеся з Швидким стартом та долучайтеся до створення власних розширень!
Джерело: Kubernetes Blog