METR Переглянуто: Відкриття метрики автономії ШІ у виконанні тривалих завдань

Опубліковано: 19 березня 2025 року, 16:00 GMT
Резюме: У цій роботі ми пропонуємо новий підхід до оцінки продуктивності штучного інтелекту (ШІ), аналізуючи тривалість завдань, які ці системи можуть виконувати автономно. Протягом останніх шести років можливості таких систем зросли експоненційно, причому часовий горизонт фактично подвоюється кожні 7 місяців. Екстраполяція цих тенденцій свідчить про те, що найближчими роками агенти ШІ зможуть виконувати складні, багатоетапні проекти, для яких зараз потрібні дні або навіть тижні людських зусиль.
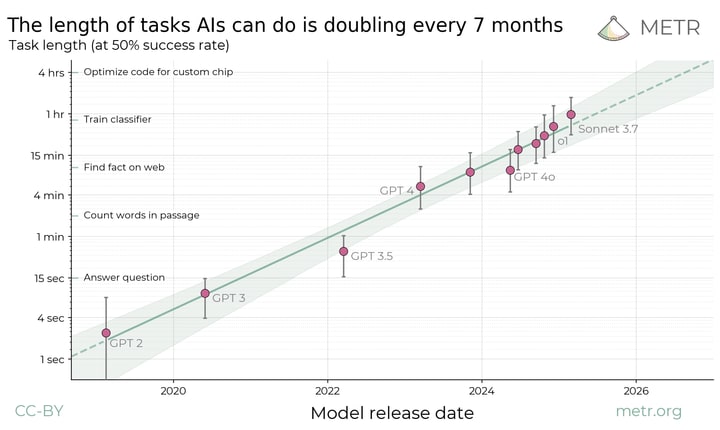
Наш показник оцінює тривалість (на основі часу експерта) завдань, які передові системи ШІ можуть виконувати автономно з 50% успішністю. Затінена область, що відокремлює 95% довірчий інтервал, розрахований через ієрархічний бутстреп на різноманітних типах завдань, підкреслює надійність нашого вимірювання.
Повна стаття | Репозиторій на GitHub
Вступ: Зв’язок між продуктивністю ШІ та реальним застосуванням
Прогнозування розвитку технологій ШІ є критично важливим для використання їх переваг та зменшення можливих ризиків. Хоча сучасні передові моделі демонструють надлюдську продуктивність у завданнях, таких як прогнозування тексту та виклики в галузі знань, вони все ще мають труднощі з координацією серії дій протягом тривалого часу. Ця невідповідність між перевагою в тестах та практичним застосуванням підкреслює важливість нашого показника: здатності виконувати тривалі завдання, що вимірюються за людським часом.
На технічному рівні ми аналізуємо продуктивність, підганяючи логістичні криві до рівня успішності кожної моделі в спектрі визначених людьми тривалостей завдань. Точка, в якій ці криві перетинають фіксований поріг надійності — наприклад, 50% — слугує індикатором ефективного часового горизонту моделі. Практично, хоча моделі, такі як Claude 3.7 Sonnet, дуже добре справляються із завданнями тривалістю до кількох хвилин, їхня надійність різко падає для завдань, що вимагають кілька годин експертного людського часу.
Технічний аналіз: Методологія та оцінка
Це дослідження використовує широкий набір даних про багатоетапні програмні та логічні завдання. Для кожного завдання ми фіксуємо час, необхідний людині-експерту для його виконання, що слугує проксі для складності завдання. Потім використовується модель логістичної регресії для відображення ймовірності успіху ШІ відносно метрики тривалості. Аналіз показує майже ідеальні показники успішності для завдань до 4 хвилин і значно нижчі показники для завдань, які перевищують 4 години. Така тенденція надійно відображає обмеження сучасних моделей ШІ щодо послідовного виконання складних кроків, незважаючи на їхні здібності в ізольованих завданнях.
Недавні експерименти, включаючи оцінки підмножин, взятих з SWE-Bench Verified, показали ще швидші темпи подвоєння — менше 3 місяців. Це свідчить про те, що методологічні деталі, такі як операціоналізація часу завдань та виключення фаз ознайомлення з кодом, можуть ще більше уточнити наше розуміння прогресу ШІ. Аналіз чутливості з використанням 10,000 випадкових варіацій підтвердив, що навіть великі невизначеності вимірювань (до 10-кратної розбіжності) зрушать прогноз досягнення місячної автономної продуктивності лише на два роки.
Крім того, наш аналіз включав ієрархічний бутстреп на сім’ях завдань, окремих завданнях та численних спробах, що забезпечує надійне відображення змінності та зовнішнього шуму в обчислених 95% довірчих інтервалах. Новини в цій галузі тепер свідчать про те, що подібні тенденції можуть спостерігатися в спеціалізованих завданнях, що виходять за межі розробки програмного забезпечення, таких як юридичне мислення та просунуті наукові відкриття, що вказує на широке застосування нашого показника.
Методологічні висновки: Надійність та перспективи
Наш підхід не є лише ретроспективним аналізом прогресу ШІ; він також відкриває нові шляхи для більш прогностичних бенчмарків. Категоризуючи завдання за часом виконання людьми, ми можемо краще узгоджувати оцінки бенчмарків з реальними наслідками. Наприклад, компанії, що розробляють інструменти віддаленого управління, тепер повинні зважати на інтелект, що стоїть за мікрорішеннями, порівняно з можливістю автономно виконувати завдання високого рівня.
Ми також підтвердили наш підхід через обширні тести чутливості. Різні розподіли завдань — від дуже коротких, рутинних до різноманітної колекції, відомої як HCAST та RE-Bench — постійно демонструють виявлену нами тенденцію експоненційного зростання з чітким сигналом на різних рівнях складності. Цей багатогранний підхід забезпечує конкретний зв’язок між передовими бенчмарками та реальними можливостями, які сприяють автоматизації на робочому місці.
Додаткові перспективи: Думки експертів та технологічні наслідки
В провідних дослідниках ШІ та експертів галузі висловили свої думки щодо нашої методології, зазначаючи, що акцент на тривалості завдань як проксі для когнітивної безперервності може революціонізувати те, як кількісно оцінюється здатність ШІ. Експерти в галузі політики ШІ стверджують, що таке розуміння буде критично важливим для управління ризиками, оскільки завдання тривалістю часто включають багатоетапні процеси прийняття рішень, які можуть вплинути на надійність та безпеку системи.
Крім того, технічні інноватори в галузі хмарних технологій та інфраструктури зацікавлені в можливості інтеграції цих показників в автоматизовані системи масштабування. Наприклад, динамічний розподіл ресурсів у хмарних обчисленнях може використовувати прогнози з нашого метрику для оптимізації розподілу навантаження по великих дата-центрах. Оскільки системи ШІ стають все більш автономними, здатність прогнозувати їхні межі виконання завдань стане важливою для розробки механізмів безпеки та надійних механізмів резервування.
Прогноз на майбутнє та вплив на реальний світ
Експоненційна тенденція, спостережена протягом останніх шести років, з часом подвоєння приблизно 7 місяців, свідчить про те, що ми на порозі трансформаційної фази в утилізації ШІ. Якщо поточні траєкторії розвитку збережуться, ми очікуємо, що впродовж 2-4 років агенти ШІ зможуть автономно виконувати проекти, що тривають цілими тижнями, що призведе до значних змін в таких галузях, як розробка програмного забезпечення та стратегічне управління.
Технічні виклики при розширенні цих можливостей численні. Окрім оптимізації існуючих архітектур, поліпшення в управлінні пам’яттю, збереженні контексту та крос-модульному мисленні будуть ключовими. Більше того, оскільки системи ШІ стануть здатні виконувати завдання тривалістю до місяця, стратегії управління етичними та операційними ризиками стануть надзвичайно важливими. Регуляторні органи та лідери галузі повинні співпрацювати, щоб забезпечити, щоб цей стрибок у можливостях супроводжувався адекватними протоколами безпеки.
Співпраця в спільноті та можливості для внесків
Ми раді поділитися нашими результатами з більш широкою спільнотою і закликаємо до повторення та розширення нашої роботи. Відкриття інфраструктури, даних та коду аналізу стало важливим кроком у цьому напрямку. Дослідники та практики запрошуються використовувати наші репозиторії на GitHub для вивчення нових доменів завдань та вдосконалення існуючих оцінок моделей.
Крім того, METR активно шукає інноваційні таланти для подальшого розвитку цього дослідження. Наша багатопрофільна команда не лише оцінює поточні бенчмарки, але й розробляє нові, які безпосередньо відображають обіцянки та ризики розширеної автономії ШІ. Зацікавлені співробітники можуть ознайомитися з переліком вакансій на нашій сторінці кар’єри, щоб приєднатися до цієї прогресивної ініціативи.
Висновок
Ця робота має значні наслідки для бенчмаркінгу, прогнозування та управління ризиками в ШІ. Вимірюючи продуктивність ШІ через призму тривалості завдань — прив’язуючи до часу завершення, визначеного експертами, — ми вводимо показник, що відображає як відносні, так і абсолютні можливості. Наш аналіз демонструє надійну експоненційну тенденцію в прогресі ШІ, що свідчить про те, що передові системи незабаром зможуть автономно управляти проектами тривалістю до місяця. З огляду на широкі переваги та супутні ризики, цей підхід пропонує значну основу як для майбутніх оцінок ШІ, так і для проактивного управління.
Поки ми продовжуємо вдосконалювати наші методології та збирати дані з нових досліджень, таких як останні відкриття з спеціалізованих оцінок, співпраця спільноти буде ключовою для перетворення цих технічних досягнень на реальні покращення.
Для подальшого обговорення, думок і співпраці, будь ласка, звертайтеся до нашої твітер-дискусії та приєднуйтесь до розмови на наших форумах спільноти.