Kubernetes Gateway API for Optimized LLM Routing

Modern generative AI and large language model (LLM) services introduce new traffic-routing requirements that traditional HTTP load balancers can’t meet. LLM inference sessions are long-lived, resource-heavy, and partially stateful: GPU-backed model servers maintain in-memory token caches, session contexts, and adapter pipelines. To address these demands, the Gateway API Inference Extension extends the Kubernetes Gateway API to provide inference-specific routing primitives, transforming any compliant ingress controller into a purpose-built Inference Gateway.
Motivation and Challenges
Unlike stateless HTTP workloads, AI/ML inference requires:
- Model-aware load balancing that accounts for GPU memory usage, per-model queue length, and adapter compatibility.
- Session affinity for chat applications to reuse token caches and reduce cold-start overhead.
- Criticality-based prioritization (e.g., interactive chat vs. batch scoring).
- Safe canary or blue-green rollouts of new model versions without request drops.
Operators often build bespoke solutions—custom Envoy filters, Kubernetes scheduler extenders, or external traffic routers—but lack a standardized, ecosystem-wide approach. The Inference Extension provides native CRDs and extension points that integrate seamlessly with Gateway API controllers like Envoy, Contour, and Kong.
Gateway API Inference Extension
The Inference Extension adds two new CRDs—InferencePool and InferenceModel—which map to specific user and platform roles:
InferencePool: Defines a scalable pool of pods (e.g., GPU or TPU servers) with shared resource constraints, GPU labels (NVIDIA T4, A100, H100), and admission policies. Platform administrators can attach Kubernetes PodDisruptionBudgets, ResourceQuotas, and NodeSelectors to enforce compliance and isolate workloads.
InferenceModel: Lets AI/ML teams publish a model-as-a-service endpoint—complete with model identity (e.g., “gpt-4-chat:v2”), optional LoRA/adapter configurations, and traffic split rules (canary, AB tests). This CRD binds to one or more InferencePools and exposes fine-grained priority classes.
By decoupling where models run (InferencePool) from what is served (InferenceModel), teams gain clarity and isolation between infra and data science domains.
How It Works
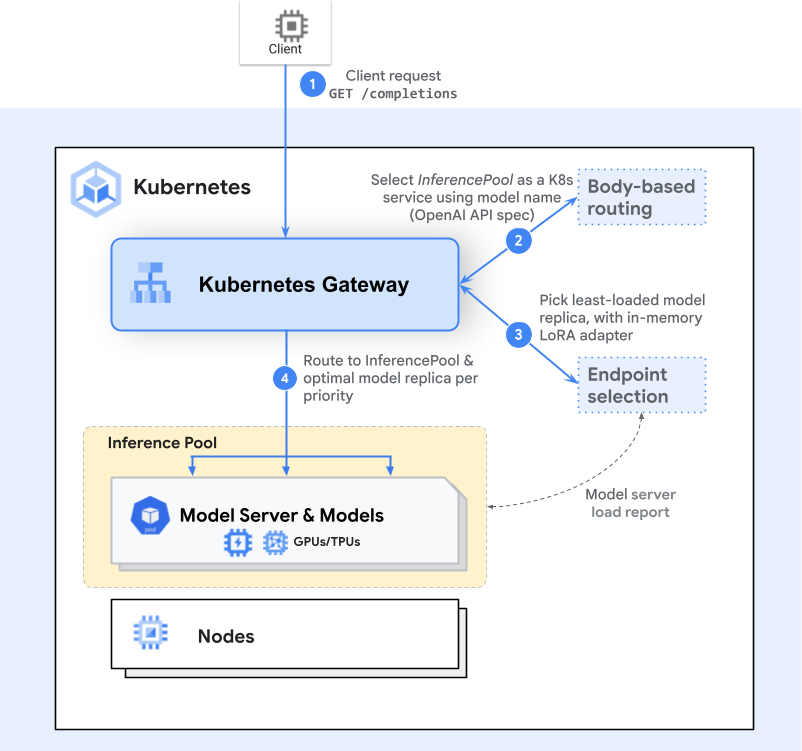
The Inference Gateway extends the standard Gateway API workflow by inserting inference-aware extension points at routing time:
- Gateway Routing: A client issues an HTTP(S) request (e.g., POST /v1/completions). The Gateway controller (Envoy, Istio Gateway) matches an HTTPRoute that references an InferencePool.
- Endpoint Selection Extension (ESE): This extension queries live metrics—GPU utilization via NVIDIA DCGM, per-pod queue length via Prometheus, loaded adapter metadata via gRPC health checks—to rank candidate endpoints.
- Inference-Aware Scheduling: Based on dynamic metrics and per-request criticality flags, the extension picks the optimal pod. High-priority interactive requests can preempt low-priority batch jobs within the same pool.
- Forwarding: Traffic is routed over the selected pod’s IP:port with session affinity headers (e.g.,
stickiness.cookie), preserving in-memory state for the duration of a chat session.
Benchmarks and Performance Analysis
We benchmarked the ESE against a vanilla Kubernetes Service for a vLLM deployment on four NVIDIA H100 (80 GB) GPUs. Using the Latency Profile Generator and the ShareGPT dataset, we ramped traffic from 100 to 1,000 QPS. Key findings:
- Throughput Parity: The ESE maintained throughput within 1–2% of the baseline across all QPS levels.
- Tail Latency Reduction: At >500 QPS, p90 token-generation latency improved by up to 30%, reducing request queuing on saturated GPUs.
- Resource Efficiency: Dynamic routing led to 15% higher GPU utilization, minimizing idle cycles and oversubscription retries.
“The ESE’s real-time scheduling decisions flatten GPU utilization curves, leading to smoother latency profiles,” notes Dr. Elena Ramos, lead ML engineer at Acme AI.
Security Considerations
Secure inference requires:
- Mutual TLS between Gateway and model servers via Kubernetes ServiceAccount tokens and cert-manager–issued certificates.
- Role-Based Access Control (RBAC) policies on InferenceModel and InferencePool objects to prevent unauthorized endpoint creation.
- NetworkPolicy rules isolating inference traffic to approved namespaces and limits on egress to external model stores.
Future releases plan to integrate secrets-management for model weights and confidential computing enclaves (e.g., Intel SGX, AMD SEV) for sensitive data deployments.
Operational Best Practices
When running the Gateway API Inference Extension at scale, consider:
- Horizontal Pod Autoscaler (HPA) wired to custom metrics: GPU memory usage, queue latency, and model load time.
- Cluster Autoscaler with GPU-aware node groups, ensuring spare capacity under peak loads.
- Integrating with MLOps pipelines (Kubeflow, Argo CD) for automated model rollout and version tracking.
- Distributed tracing (OpenTelemetry) across Gateway, extension logic, and model servers for end-to-end observability.
Roadmap
As the project advances toward GA, upcoming features include:
- Prefix-Cache-Aware Balancing integrating remote token caches.
- LoRA Adapter Pipelines for automated fine-tuning rollouts.
- Fairness and Priority policies across mixed workloads.
- HPA Integration leveraging per-model custom metrics.
- Support for multi-modal models (vision, audio, text).
- Heterogeneous accelerator pools (e.g., GPUs, TPUs, FPGAs).
- Disaggregated serving for independent scaling of encoder/decoder stages.
Summary
The Gateway API Inference Extension brings Kubernetes-native traffic management to AI/ML inference. With model-aware routing, criticality prioritization, and real-time scheduling, platform operators can self-host GenAI/LLMs efficiently and securely—while data scientists retain easy, service-oriented endpoints.
Get started: Visit the project docs, follow the Quickstart guide, and contribute your own extensions!
Source: Kubernetes Blog