Kubernetes v1.33: Нові можливості потокового отримання списків

Управління стабільністю кластерів Kubernetes стає дедалі важливішим у міру зростання вашої інфраструктури. Одним із найбільш складних аспектів експлуатації кластерів великого масштабу є обробка запитів на отримання списків, які вимагають значних обсягів даних. Це звична операція, яка в попередніх версіях могла несподівано впливати на стабільність контрольної площини. З випуском Kubernetes v1.33 спільнота представляє суттєве архітектурне вдосконалення: стрімінгове кодування для відповідей на запити списків.
Цю функцію було представлено на KubeCon EU 2025 в Амстердамі, де розробники продемонстрували в реальному часі великомасштабні операції зі списками під високим навантаженням, показуючи значне зменшення використання пам’яті.
Проблема: зайве споживання пам’яті при роботі з великими ресурсами
У версіях до v1.33 конвеєр кодування API-сервера серіалізував всю відповідь на запит списку в один безперервний байтовий буфер перед тим, як записати його за один раз через ResponseWriter.Write. Незважаючи на те, що HTTP/2 розбиває ці дані на фрейми для передачі по мережі, HTTP-сервер зберігає весь обсяг даних у пам’яті до завершення передачі. При високій затримці або перевантаженні ці буфери можуть залишатися заблокованими на десятки секунд, що призводить до тривалого та надмірного споживання пам’яті в процесі kube-apiserver.
При масштабуванні відповіді на запити списків можуть досягати сотень мегабайт, а кілька одночасних запитів можуть швидко призвести до зростання споживання пам’яті, що загрожує подіям Out-of-Memory (OOM). Додатково, пакет Go encoding/json використовує sync.Pool для повторного використання буферів. Хоча це ефективно для стабільних навантажень, спорадичні великі списки збільшують буфери пулу, які зберігаються навіть після завершення великого запиту, що призводить до неефективного повторного використання надмірних алокацій при наступних малих запитах.
Протокольні буфери забезпечують високу продуктивність серіалізації для окремих повідомлень, але не оптимізовані для великих колекцій у вигляді монолітних буферів. Як попереджає офіційний посібник:
“Як правило, якщо ви працюєте з повідомленнями, більшими за один мегабайт, можливо, настав час розглянути альтернативну стратегію.” — Техніки протокольних буферів
Стрімінговий кодувальник для відповідей на запити списків
Новий стрімінговий кодувальник у v1.33 націлений на поле Items у об’єктах списку, яке зазвичай містить основну частину даних. Замість того, щоб накопичувати весь масив, кодувальник випускає відкриваючу дужку JSON-масиву, а потім серіалізує кожен елемент окремо, використовуючи json.Encoder Go, викликаючи ResponseWriter.(http.Flusher) після кожного елемента. Ця стратегія, що базується на частковій передачі, дозволяє збирачу сміття відразу звільняти буфер кожного елемента після передачі, що значно зменшує пікове споживання пам’яті.
За лаштунками NegotiatedSerializer API-сервера генерує runtime.StreamSerializer, налаштований з параметрами стрімінгу. Перед активацією кодувальник ретельно перевіряє теги структур Go, щоб забезпечити байт за байтом сумісність з попереднім кодувальником. Усі поля, що не входять до Items, обробляються за стандартним шляхом, що гарантує ідентичне форматування виходу без змін з боку клієнта.
Механіка реалізації та API Go
Патч v1.33 додає новий StreamEncoder в k8s.io/apiserver/pkg/streaming і розширює serializer/json з параметром WithStreamingList. Ланцюг обробників впроваджує цей кодувальник на основі функціонального ключа StreamingListEncoding. Нижче наведено спрощений фрагмент:
streamingSerializer := json.NewSerializer(...).WithStreamingList()
handler.ServeHTTP = negotiate.Serve(streamingSerializer, ...)
Запити до /api/v1/pods або будь-якої кінцевої точки списку автоматично використовують стрімінговий шлях, коли функціональний ключ увімкнено. Реалізація підтримує як часткову передачу для HTTP/1.1, так і стрімінг на основі фреймів для HTTP/2, без змін в поведінці клієнтів.
Сумісність і стратегія впровадження
Запроваджена як бета-версія за замовчуванням у v1.33, функція StreamingListEncoding дозволяє кластерам відмовитися від неї, якщо це необхідно. Статус бета-версії забезпечує плавний перехід — SIG API Machinery планує просунути цю функцію до GA у v1.34, після отримання відгуків від спільноти та подальшої валідації в продуктивних середовищах. Усі основні клієнти, включаючи kubectl (через client-go) та популярні інформаційні панелі, обробляють стрімінг прозоро, що робить міграцію безперешкодною.
Покращення продуктивності, які ви помітите
- Зменшене споживання пам’яті: Пікове споживання пам’яті для великих операцій зі списками зменшується більш ніж на 90%, звільняючи ресурси для інших функцій API-сервера.
- Покращена масштабованість: API-сервер може витримувати вищу одночасність запитів на списки, особливо в CI/CD конвеєрах та GitOps робочих процесах, які часто запитують стан кластера.
- Підвищена стабільність: Нижчі піки пам’яті значно зменшують ризики вбивства OOM, покращуючи доступність та надійність критичних компонентів контрольної площини.
- Ефективне використання ресурсів: Завдяки миттєвому звільненню буферів зменшується навантаження на збирач сміття, а затримки під навантаженням зменшуються.
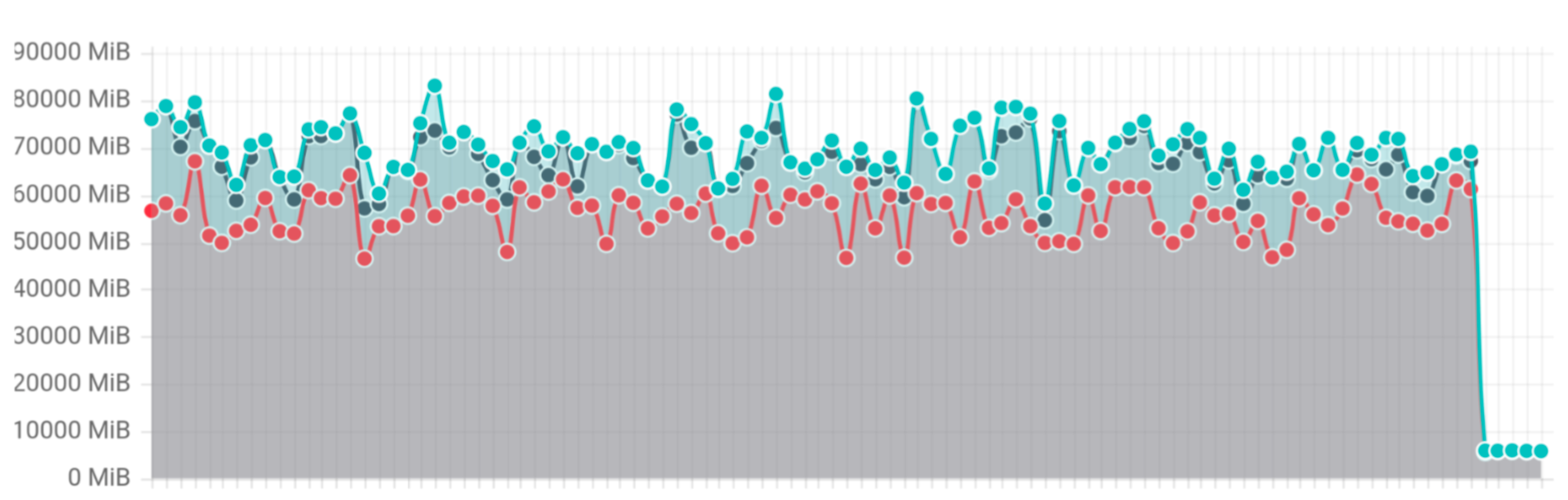
Результати бенчмарків
Для перевірки покращень команда Kubernetes представила новий бенчмарк list у k8s.io/apimachinery. Тест генерує десять одночасних запитів на списки, кожен з яких повертає 1 ГБ даних про поди. Результати показують зменшення споживання пам’яті в 20 разів — з ~70 ГБ пікових до ~3 ГБ, а затримки в хвості покращилися на 15% на 95-му процентилі. Пропускна здатність мережі та використання CPU залишалися стабільними, підтверджуючи, що накладні витрати на кодування додають незначні витрати на CPU.
Майбутня робота та дорожня карта
Дивлячись у майбутнє, SIG API Machinery досліджує стратегії стрімінгу для відповідей на запити Watch і масових операцій Patch. Ранні прототипи націлені на стрімінг на основі gRPC для внутрішніх сервісів, що потенційно об’єднає потоки JSON та Protobuf. Наступний реліз v1.34 завершить GA для стрімінгового кодування списків та представить оптимізації для продуктивності списків CustomResourceDefinition (CRD).
“Стрімінгове кодування списків є фундаментальним кроком до підвищення ефективності API-сервера Kubernetes на масштабах. Ми раді розширити цю модель на інші операції з високим обсягом у майбутніх релізах.” — Лідер SIG API Machinery