Kubernetes v1.33: Streaming List Responses

Managing Kubernetes cluster stability becomes increasingly critical as your infrastructure grows. One of the most challenging aspects of operating large-scale clusters has been handling List requests that fetch substantial datasets—a common operation that, in earlier versions, could unexpectedly impact your control plane’s stability. With the release of Kubernetes v1.33, the community introduces a major architectural improvement: streaming encoding for List responses.
The feature was unveiled at KubeCon EU 2025 in Amsterdam, where maintainers presented live demos of large-scale cluster List operations under high contention, showcasing dramatic memory reductions in real time.
The problem: unnecessary memory consumption with large resources
In versions prior to v1.33, the API server’s encoding pipeline would serialize an entire List response into a single contiguous byte buffer before writing it in one go via ResponseWriter.Write. Even though HTTP/2 splits this data into frames for network transmission, the HTTP server maintains the full payload in memory until transmission completes. Under high latency or congestion, these buffers may remain pinned for tens of seconds, leading to prolonged, excessive memory usage in the kube-apiserver process.
At scale, List responses can reach hundreds of megabytes, and multiple simultaneous requests can rapidly escalate memory consumption, risking Out-of-Memory (OOM) events. Compounding this, Go’s encoding/json package uses sync.Pool to recycle buffers. While efficient for steady workloads, sporadic large Lists inflate pool buffers that persist even after the large request completes, causing subsequent small requests to inefficiently reuse oversized allocations.
Protocol Buffers offer high-performance serialization for individual messages, but are not optimized for giant collections as monolithic buffers. As the official guide warns:
“As a general rule of thumb, if you are dealing in messages larger than a megabyte each, it may be time to consider an alternate strategy.” — Protocol Buffers Techniques
Streaming encoder for List responses
The new streaming encoder in v1.33 targets the Items field in List objects, which typically holds the bulk of the payload. Rather than accumulating the entire array, the encoder emits the JSON array’s opening bracket, then serializes each item individually using Go’s json.Encoder, invoking ResponseWriter.(http.Flusher) after each element. This chunked-by-item strategy allows the garbage collector to reclaim each item’s buffer immediately after transmission, dramatically reducing the peak memory footprint.
Behind the scenes, the API server’s NegotiatedSerializer generates a runtime.StreamSerializer configured with streaming options. Before activating, the encoder rigorously verifies Go struct tags to guarantee byte-for-byte compatibility with the legacy encoder. All fields outside Items are processed via the standard path, ensuring identical output formatting with zero client-side modifications.
Implementation mechanics and Go API
The v1.33 patch adds a new StreamEncoder in k8s.io/apiserver/pkg/streaming and extends serializer/json with a WithStreamingList option. The handler chain injects this encoder based on the StreamingListEncoding feature gate. Below is a simplified snippet:
streamingSerializer := json.NewSerializer(...).WithStreamingList()
handler.ServeHTTP = negotiate.Serve(streamingSerializer, ...)
Requests to /api/v1/pods or any List endpoint automatically use the streaming path when the feature gate is enabled. The implementation supports both chunked transfer for HTTP/1.1 and frame-based streaming for HTTP/2, with no change in client behaviour.
Compatibility and rollout strategy
Introduced as a default-on beta in v1.33, the StreamingListEncoding feature gate allows clusters to opt out if needed. Beta status ensures a smooth transition—SIG API Machinery plans to promote the feature to GA in v1.34, following community feedback and further validation in production environments. All major clients, including kubectl (via client-go) and popular dashboards, handle streaming transparently, making migration seamless.
Performance gains you’ll notice
- Reduced Memory Consumption: Peak memory usage for large List operations drops by over 90%, freeing up resources for other API server functions.
- Improved Scalability: The API server can sustain higher concurrency of List requests, especially in CI/CD pipelines and GitOps workflows that frequently query cluster state.
- Increased Stability: Lower memory spikes dramatically reduce OOM kill risks, improving uptime and reliability for critical control plane components.
- Efficient Resource Utilization: By releasing buffers immediately, GC overhead falls and latency spikes under load diminish.
Benchmark results
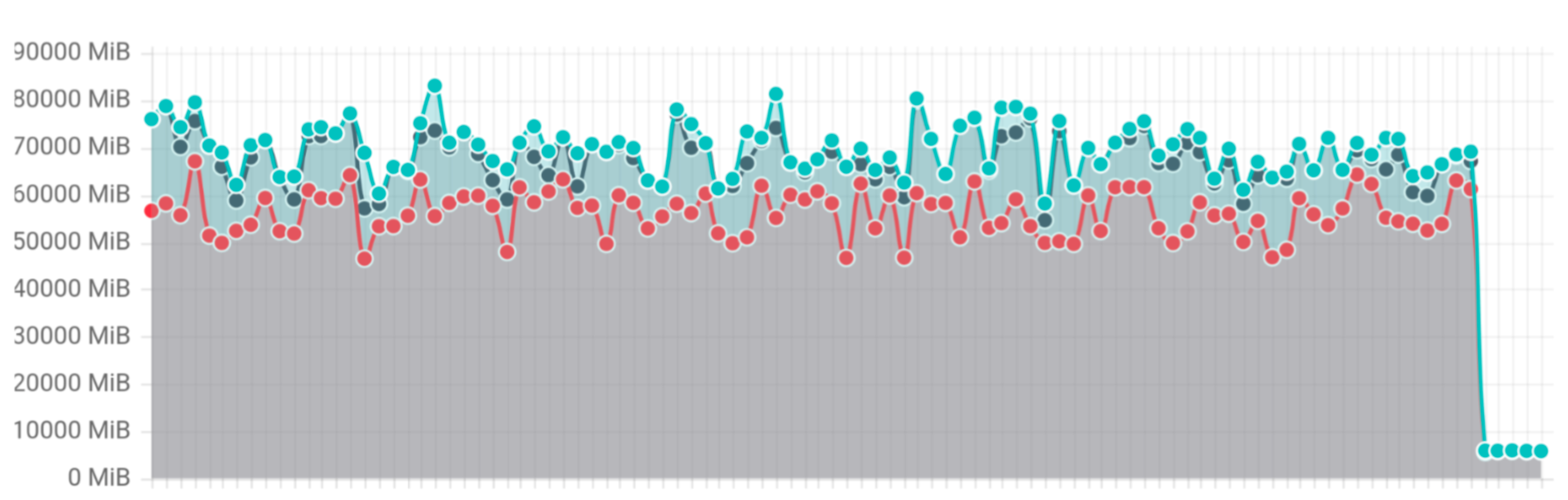
To validate the improvements, the Kubernetes team introduced a new list benchmark in k8s.io/apimachinery. The test issues ten concurrent List requests, each returning 1 GB of Pod data. Results show a 20× memory reduction—from ~70 GB peak down to ~3 GB—and tail latencies improved by 15% under 95th percentile. Network throughput and CPU utilization remained stable, confirming that encoding overhead adds negligible CPU cost.
Future work and roadmap
Looking ahead, SIG API Machinery is exploring streaming strategies for Watch responses and bulk Patch operations. Early prototyping targets gRPC-based streaming for internal services, potentially unifying JSON and Protobuf streams. The upcoming v1.34 release will finalize GA for streaming List encoding and introduce optimizations for CustomResourceDefinition (CRD) List performance.
“Streaming List encoding is a foundational step towards making the Kubernetes API server more efficient at scale. We’re excited to extend this model to other high-volume operations in future releases.” — SIG API Machinery Lead